Data Science is a detailed study of the flow of information from the colossal amounts of data present in an organization’s repository. It involves obtaining meaningful insights from raw and unstructured data which is processed through analytical, programming, and business skills. Let’s get started with our ‘What is Data Science?’ blog
Importance of Data Science: The Current Scenario
In a world that is increasingly becoming a digital space, organizations deal with zettabytes and yottabytes of structured and unstructured data every day. Evolving technologies have enabled cost savings and smarter storage spaces to store critical data.
Currently, in the industry, there is a huge need for skilled and certified Data Scientists. They are among the highest-paid professionals in the IT industry. According to Forbes, ‘the best job in America is of a Data Scientist with an average annual salary of $110,000’. Only a few people have the capability to process it and derive valuable insights out of it.
 Furthermore, looking at the huge and ever-increasing requirements, McKinsey has predicted that there will be a 50 percent gap in the supply of Data Scientists versus its demand in the upcoming years. That’s why in this blog we are talking about ‘What is Data Science?’
Furthermore, looking at the huge and ever-increasing requirements, McKinsey has predicted that there will be a 50 percent gap in the supply of Data Scientists versus its demand in the upcoming years. That’s why in this blog we are talking about ‘What is Data Science?’
In recent years, there is a huge growth in the field of Internet of Things (IoT), due to which 90 percent of the data has been generated in the current world. Every day, 2.5 quintillion bytes of data are generated, and it is more accelerated with the growth of IoT. This data comes from all possible sources such as:
- Sensors used in shopping malls to gather shoppers’ information
- Posts on social media platforms
- Digital pictures and videos captured in our phones
- Purchase transactions made through e-commerce
This data is known as big data.
Companies are flooded with colossal amounts of data. Thus, it is very important to know what to do with this exploding data and how to utilize it.
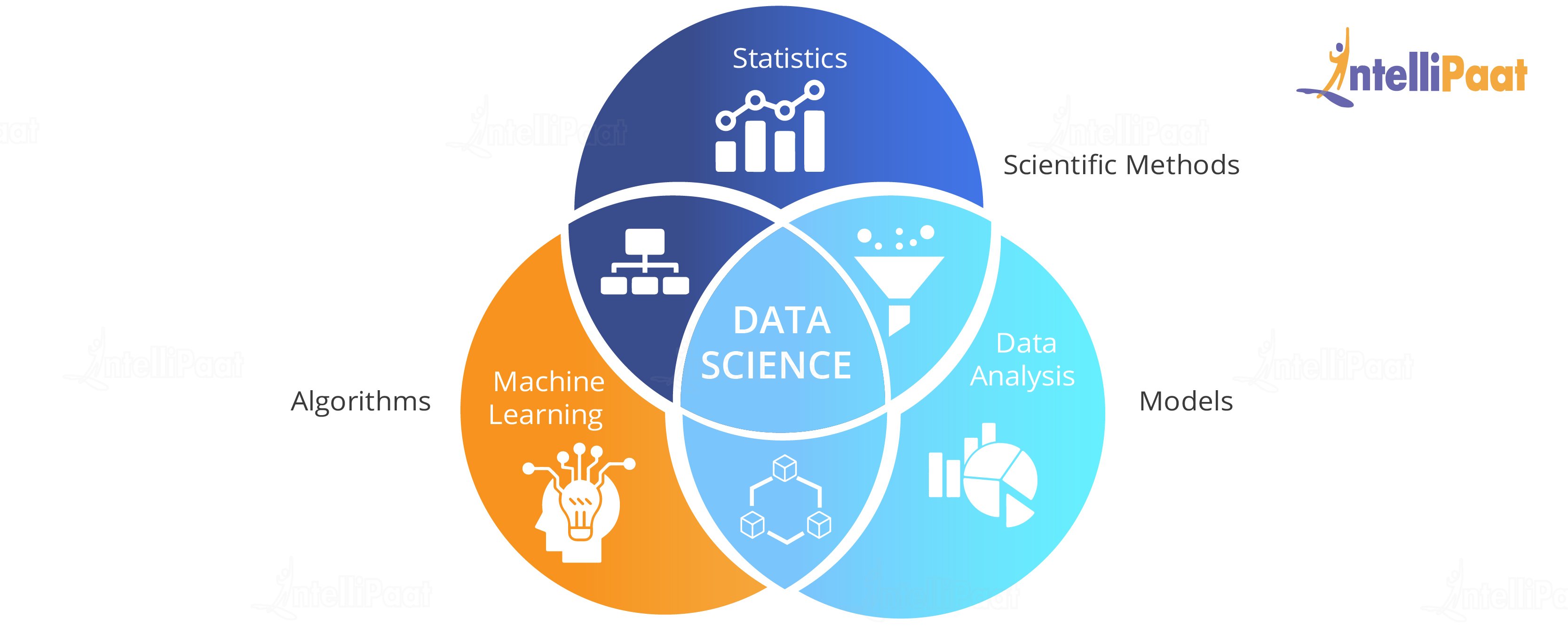
It is here, the concept of Data Science comes into the picture. Data Science brings together a lot of skills like statistics, mathematics, and business domain knowledge and helps an organization find ways to:
- Reduce costs
- Get into new markets
- Tap on different demographics
- Gauge the effectiveness of a marketing campaign
- Launch a new product or service
And the list is endless!
Therefore, regardless of the industry vertical, Data Science is likely to play a key role in your organization’s success.
Look at the below infographic, and you will be able to understand how Data Science is creating its impression:
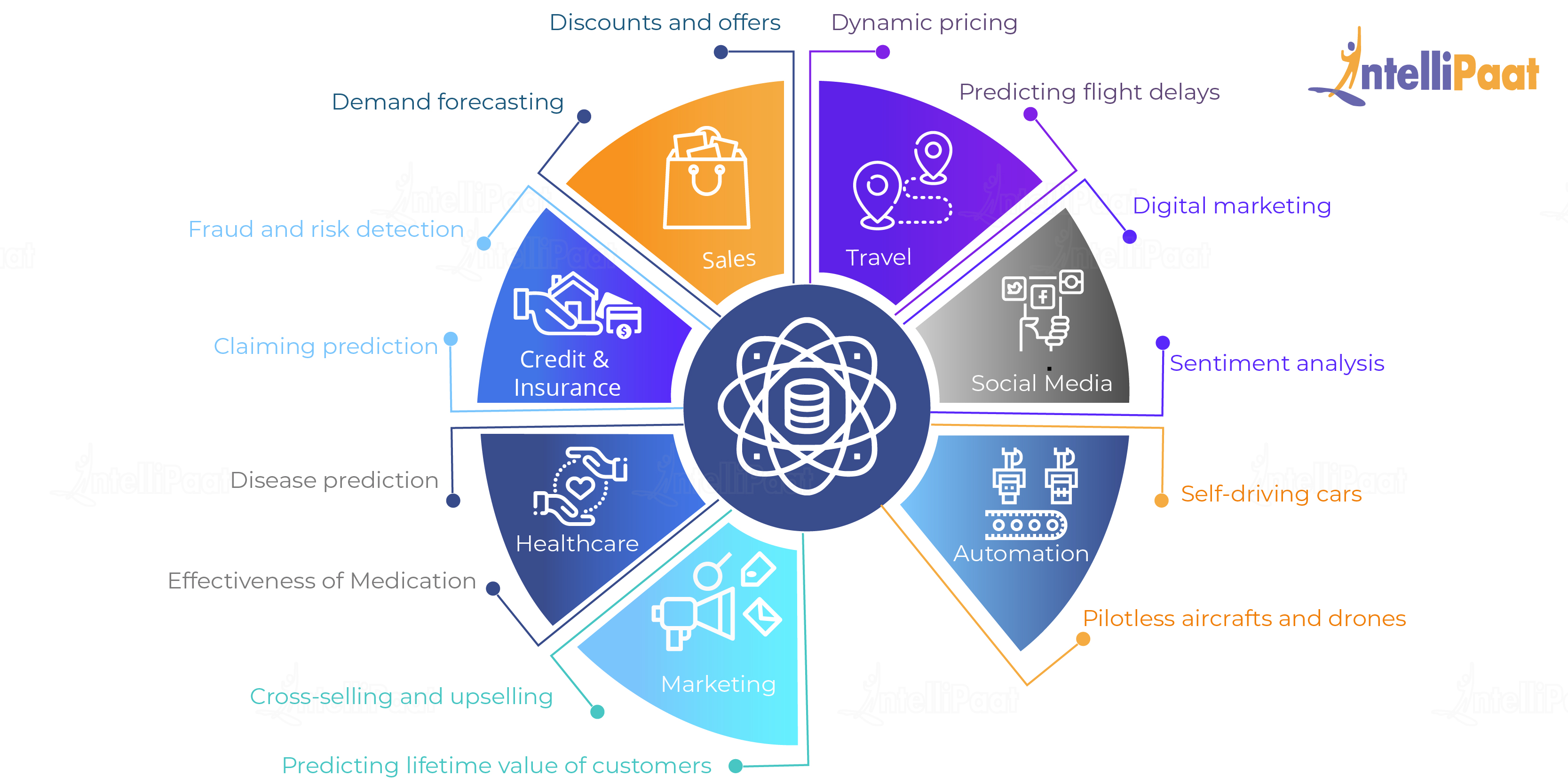
How do top industry players use Data Science?
In this section of the ‘What is Data Science?’ blog, we will look at how top industry players like Google, Amazon, and Visa are using Data Science. IT organizations need to address their complex and expanding data environments in order to identify new value sources, exploit opportunities, and grow or optimize themselves, efficiently. Here, the deciding factor for an organization is ‘what value they extract from their data repository using analytics and how well they present it’. Below, we list some of the biggest and best companies that are hiring Data Scientists at top-notch salaries.



Data Science Life Cycle
For a better understanding of ‘What is Data Science?’, let’s explore its life cycle. Suppose, Mr. X is the owner of a retail store and his goal is to improve the sales of his store by identifying the drivers of sales. To accomplish the goal, he needs to answer the following questions:
- Which are the most profitable products in the store?
- How are the in-store promotions working?
- Are the product placements effectively deployed?
His primary aim is to answer these questions which would surely influence the outcome of the project. Hence, he appoints you as a Data Scientist. Let’s solve this problem using the Data Science life cycle.
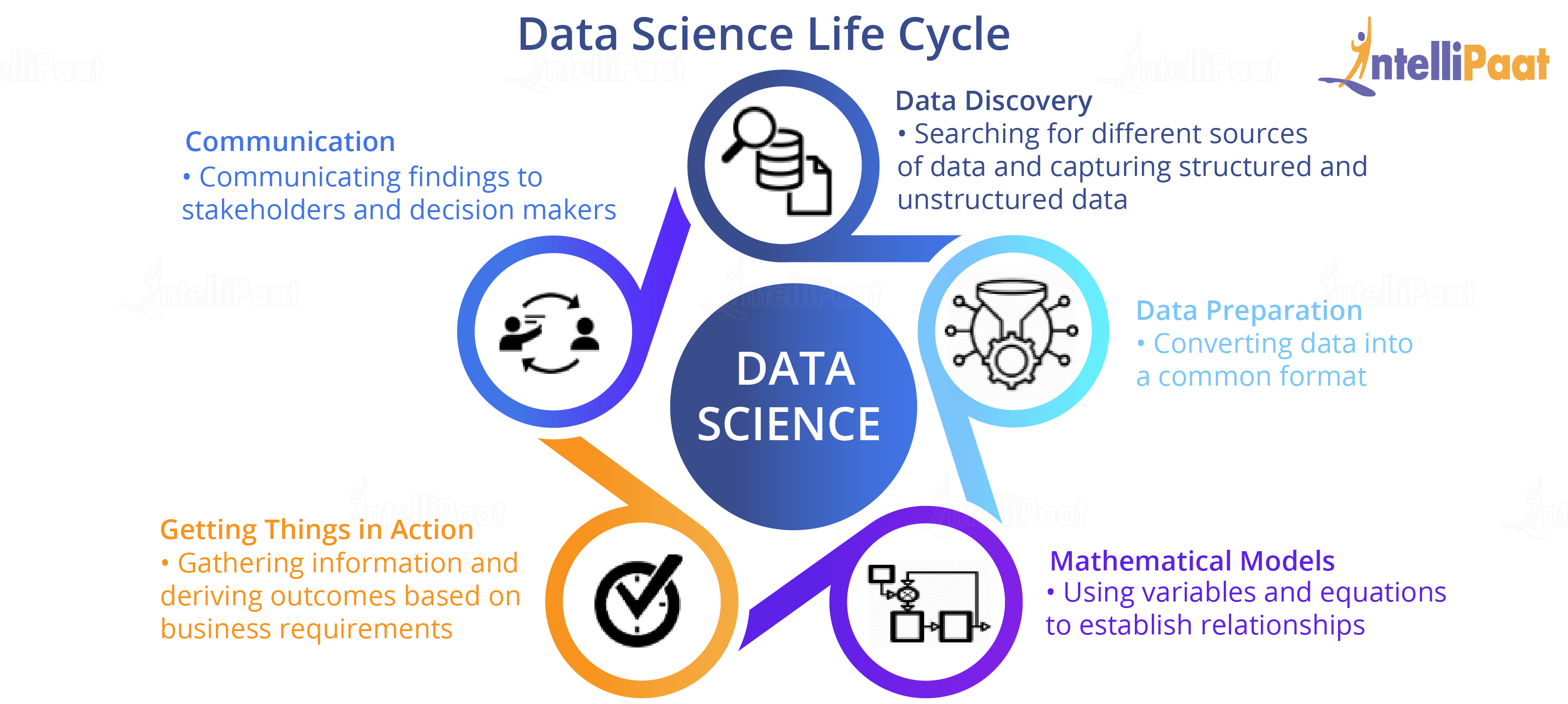
Data Discovery
The first phase in the Data Science life cycle is data discovery for any Data Science problem. It includes ways to discover data from various sources which could be in an unstructured format like videos or images or in a structured format like in text files, or it could be from relational database systems. Organizations are also peeping into customer social media data, and the like, to understand customer mindset better.
In this stage, as a Data Scientist, our objective would be to boost the sales of Mr. X’s retail store. Here, factors affecting the sales could be:
- Store location
- Staff
- Working hours
- Promotions
- Product placement
- Product pricing
- Competitors’ location and promotions, and so on
Keeping these factors in mind, we would develop clarity on the data and procure this data for our analysis. At the end of this stage, we would collect all data that pertain to the elements listed above.
Data Preparation
Once the data discovery phase is completed, the next stage is data preparation. It includes converting disparate data into a common format in order to work with it seamlessly. This process involves collecting clean data subsets and inserting suitable defaults, and it can also involve more complex methods like identifying missing values by modeling, and so on. Once the data cleaning is done, the next step is to integrate and create a conclusion from the dataset for analysis. This involves the integration of data which includes merging two or more tables of the same objects, but storing different information, or summarizing fields in a table using aggregation. Here, we would also try to explore and understand what patterns and values our datasets have.
Mathematical Models
Do you know, all Data Science projects have certain mathematical models driving them. These models are planned and built by the Data Scientists in order to suit the specific need of the business organization. This might involve various areas of the mathematical domain including statistics, logistic and linear regression, differential and integral calculus, etc. Various tools and apparatus used in this regard could be R statistical computing tools, Python programming language, SAS advanced analytical tools, SQL, and various data visualization tools like Tableau and QlikView.
Also, to generate a satisfactory result, one model might not be enough. We need to use two or more models. In this scenario, a Data scientist will create a group of models. After measuring the models, he/she will revise the parameters and fine-tune them for the next modeling run. This process will continue until the Data Scientist is pretty sure that he/she has found the best model.
In this stage, as a Data Scientist, you will build mathematical models based on the business needs of Mr. X, i.e., based on if product A or product B is the most profitable in the store, whether the product placements are effectively working in the store, etc.
Getting Things in Action
Once the data is prepared and the models are built, it is time to get these models working in order to achieve the desired results. There might be various discrepancies and a lot of troubleshooting that might be needed, and thus the model might have to be tweaked. Here, model evaluation explains the performance of the model.
In this stage, you as a Data Scientist will gather information and derive outcomes based on the business requirements of Mr. X.
Communication
Communicating the findings is the last but not the least step in a Data Science endeavor. In this stage, the Data Scientist needs to be a liaison between various teams and should be able to seamlessly communicate his findings to key stakeholders and decision-makers in the organization so that actions can be taken based on the recommendations of the Data Scientist.
In our example, based on the findings, you will communicate and recommend certain changes in the business strategy so that Mr. X can earn the maximum profit.
Data Science Components
Now, in this ‘What is Data Science?’ blog, we will discuss some of the key components of Data Science, which are:
- Data (and Its Various Types)
The raw dataset is the foundation of Data Science, and it can be of various types like structured data (mostly in a tabular form) and unstructured data (images, videos, emails, PDF files, etc.)
- Programming (Python and R)
Data management and analysis is done by computer programming. In Data Science, two programming languages are most popular: Python and R.
- Statistics and Probability
Data is manipulated to extract information out of it. The mathematical foundation of Data Science is statistics and probability. Without having a clear knowledge of statistics and probability, there is a high possibility of misinterpreting data and reaching at incorrect conclusions. That’s the reason why statistics and probability play a crucial role in Data Science.
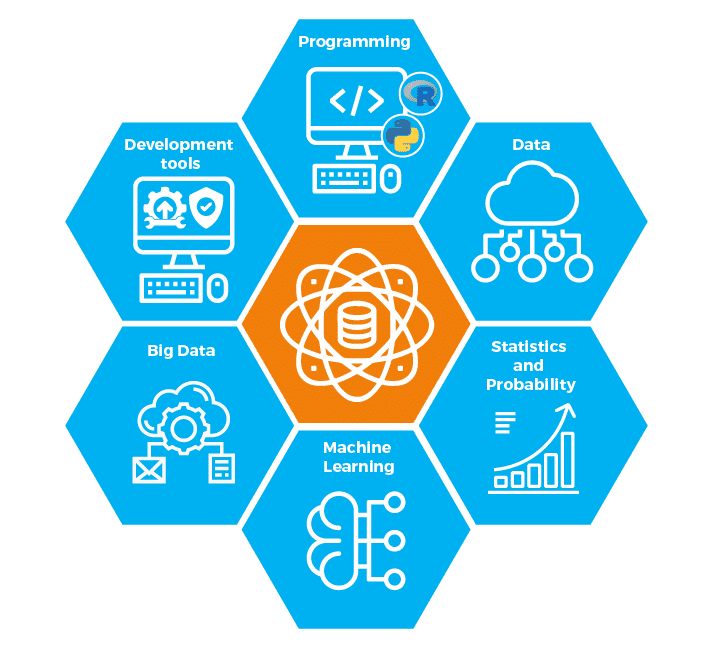
- Machine Learning
As a Data Scientist, every day, you will be using Machine Learning algorithms such as regression and classification methods. It is very important for a Data Scientist to know Machine learning as a part of their job so that they can predict valuable insights from available data.
- Big Data
In the current world, raw data is compared with crude oil, and the way we extract refined oil from the crude oil, by applying Data Science, we can extract different kinds of information from raw data. Different tools used by Data Scientists to process big data are Java, Hadoop, R, Pig, Apache Spark, etc.

Also Read :5 online data science courses for tech-curious professionals
How does Intellipaat help you in making a career in Data Science?
Now, you can answer the question ‘What is Data Science?’ and know that Data Science is not all about money. It also allows you to gain immense knowledge throughout your career. So, it is this heady mix of money and deep domain knowledge that makes Data Science such an enviable career option for budding technology professionals.
Intellipaat provides huge opportunities to the aspirants who are willing to establish themselves as all-rounders in this area. Hence, getting trained inData Sciencetechnologies through courses offered by Intellipaat will be the best career move you will ever make. Intellipaat offers a wide range of courses dedicated to providing you an end-to-end knowledge about the trending and highly in-demandData Science skillsin this domain.
It was not joking when Harvard Business Review reported that Data Science is the hottest job opportunity of the twenty-first century. Today, if any digitally driven organization is starved of data even for a short duration of time, then it loses its competitive edge. Data Scientists help organizations make sense of their customers, markets, and the business as a whole.
If you want to become a Google Data Scientist at the best salary, then you need to be at the top of your game. If you are wondering how to learn Data Science, then Intellipaat is just the right place to start with your incredible Data Science journey.
Source :: Intellipat
Author Profile

Latest entries
 Tips & TricksNovember 7, 2025master_not_discovered_exception in Palo Alto Networks Log Collector
Tips & TricksNovember 7, 2025master_not_discovered_exception in Palo Alto Networks Log Collector Tech NewsAugust 17, 2025Malware Analysis For Remcos Remote Access Trojan (RAT)
Tech NewsAugust 17, 2025Malware Analysis For Remcos Remote Access Trojan (RAT) Tech NewsJune 10, 2025How to register and install iOS 26, iPadOS 26, and macOS Tahoe
Tech NewsJune 10, 2025How to register and install iOS 26, iPadOS 26, and macOS Tahoe Tech NewsJune 1, 2025How to Install Cisco and Juniper Images in EVE-NG
Tech NewsJune 1, 2025How to Install Cisco and Juniper Images in EVE-NG



2 Comments
tanwar007 · July 22, 2021 at 6:54 pm
Nice post power bi training
bladebreaker · July 27, 2021 at 2:11 pm
Nice post devops online training