Big data is an evolving term that describes a large volume of structured, semi-structured and unstructured data that has the potential to be mined for information and used in machine learning projects and other advanced analytics applications.
Big data is often characterized by the 3Vs: the extreme volume of data, the wide variety of data types and the velocity at which the data must be processed. Those characteristics were first identified by Gartner analyst Doug Laney in a report published in 2001. More recently, several other Vs have been added to descriptions of big data, including veracity, value and variability. Although big data doesn’t equate to any specific volume of data, the term is often used to describe terabytes, petabytes and even exabytes of data captured over time.
Breaking down the Vs of big data
Such voluminous data can come from myriad different sources, such as business transaction systems, customer databases, medical records, internet clickstream logs, mobile applications, social networks, the collected results of scientific experiments, machine-generated data and real-time data sensors used in internet of things (IoT) environments. Data may be left in its raw form or preprocessed using data mining tools or data preparation software before it’s analyzed.
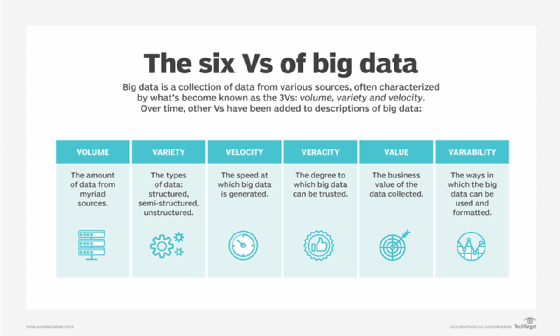
Big data also encompasses a wide variety of data types, including structured data in SQLdatabases and data warehouses, unstructured data, such as text and document files held in Hadoop clusters, or NoSQL systems, and semi-structured data, such as web server logs or streaming data from sensors. Further, big data includes multiple, simultaneous data sources, which may not otherwise be integrated. For example, a big data analytics project may attempt to gauge a product’s success and future sales by correlating past sales data, return data and online buyer review data for that product.
Velocity refers to the speed at which big data is generated and must be processed and analyzed. In many cases, sets of big data are updated on a real- or near-real-time basis, compared with daily, weekly or monthly updates in many traditional data warehouses. Big data analytics projects ingest, correlate and analyze the incoming data, and then render an answer or result based on an overarching query. This means data scientists and other data analysts must have a detailed understanding of the available data and possess some sense of what answers they’re looking for to make sure the information they get is valid and up to date. Velocity is also important as big data analysis expands into fields like machine learning and artificial intelligence (AI), where analytical processes automatically find patterns in the collected data and use them to generate insights.

Data veracity refers to the degree of certainty in data sets. Uncertain raw data collected from multiple sources, such as social media platforms and webpages, can cause serious data qualityissues that may be difficult to pinpoint. For example, a company that collects data from hundreds of sources may be able to identify inaccurate data, but its analysts need data lineage information to trace where the data is stored so they can correct the issues.
Bad data leads to inaccurate analysis and may undermine the value of business analytics because it can cause executives to mistrust data as a whole. The amount of uncertain data in an organization must be accounted for before it is used in big data analytics applications. IT and analytics teams also need to ensure that they have enough accurate data available to produce valid results.
Some data scientists also add a fifth V – value — to the list of characteristics of big data. As explained above, not all data collected has real business value and the use of inaccurate data can weaken insights provided by analytics applications. It’s critical that organizations employ practices such as data cleansing and confirm that data relates to relevant business issues before they use it in a big data analytics project.

Variability also often applies to sets of big data, which are less consistent than conventional transaction data and may have multiple meanings or be formatted in different ways from one data source to another — things that further complicate efforts to process and analyze the data. Some people ascribe even more Vs to big data — data scientists and consultants have created various lists with between seven and 10 Vs.
Big data collection practices, praise and criticism
For many years, companies have had few restrictions on the type of data they collect from their customers. Companies use the big data accumulated in their systems to improve operations, provide better customer service, create personalized marketing campaigns based on specific customer preferences, and, ultimately, increase profitability. Big data is also used by medical researchers to identify disease risk factors. Data derived from electronic health records, social media, the web and other sources provides up-to-the-minute information on infectious disease threats or outbreaks.

But as data collection and use has increased, so has data misuse. Concerned citizens who have experienced the mishandling of their data or been victims of a data breach are calling for laws around data collection transparency and consumer data privacy.
The outcry about personal privacy violations led the European Union to pass the General Data Protection Regulation (GDPR), which took effect in May 2018; it limits the types of data that organizations can collect and requires opt-in consent from individuals. While there aren’t similar laws in the U.S., government officials are investigating data handling practices, specifically among companies that collect consumer data and sell it to other companies for unknown use.
How big data is stored and processed
The need to handle big data velocity imposes unique demands on the underlying compute infrastructure. The computing power required to quickly process huge volumes and varieties of data can overwhelm a single server or server cluster. Organizations must apply adequate processing capacity to big data tasks to achieve the required velocity. This can potentially demand hundreds or thousands of servers that can distribute the processing work and operate collaboratively in a clustered architecture.
Achieving such velocity in a cost-effective manner is also a challenge. Many enterprise leaders are reticent to invest in an extensive server and storage infrastructure to support big data workloads, particularly ones that don’t run 24/7. As a result, public cloud computing is now a primary vehicle for hosting big data systems. A public cloud provider can store petabytes of data and scale up the required number of servers just long enough to complete a big data analytics project. The business only pays for the storage and compute time actually used, and the cloud instances can be turned off until they’re needed again.
To improve service levels even further, public cloud providers offer big data capabilities through managed services that include highly distributed Apache Hadoop compute instances, the Apache Spark processing engine and related big data technologies. Amazon Elastic MapReduce (EMR) from Amazon Web Services (AWS) is one example of a big data service that runs in a public cloud; others include Microsoft’s Azure HDInsight and Google Cloud Dataproc. In cloud environments, big data can be stored in the Hadoop Distributed File System (HDFS) or in lower-cost cloud object storage, such as Amazon Simple Storage Service (S3); NoSQL databases are another option in the cloud for applications that are a good fit for them.

For organizations that want to deploy on-premises big data systems, commonly used Apache open source technologies in addition to Hadoop and Spark include Yet Another Resource Negotiator (YARN), Hadoop’s built-in resource manager and job scheduler; the MapReduce programming framework; Kafka, an application-to-application messaging and data streaming platform; the HBase database; and SQL-on-Hadoop query engines like Drill, Hive, Impala and Presto. Users can install the open source versions of the technologies themselves or turn to commercial big data platforms offered by Cloudera, Hortonworks and MapR Technologies, which are also supported in the cloud. However, Cloudera and Hortonworks agreed to merge in October 2018, which likely will reduce the number of available on-premises platforms to two.
The human side of big data analytics
Ultimately, the value and effectiveness of big data depends on the workers tasked with understanding the data and formulating the proper queries to direct big data analytics projects. Some big data tools meet specialized niches and allow less technical users to use everyday business data in predictive analytics applications. Other technologies, such as Hadoop-based big data appliances, help businesses implement a suitable compute infrastructure to tackle big data projects, while minimizing the need for hardware and distributed software know-how.
But these tools only address limited use cases. Many other big data tasks, such as determining the effectiveness of a new drug, can require substantial scientific and computational expertise from an analytics team. But finding such expertise can be a challenge: There is currently a shortage of data scientists and other analysts who have experience working with big data in a distributed, open source environment.
Big data can be contrasted with small data, another evolving term that’s often used to describe data whose volume and format can be easily used for self-service analytics. A commonly quoted axiom is that “big data is for machines; small data is for people.”
Author Profile

Latest entries
 Tips & TricksNovember 7, 2025master_not_discovered_exception in Palo Alto Networks Log Collector
Tips & TricksNovember 7, 2025master_not_discovered_exception in Palo Alto Networks Log Collector Tech NewsAugust 17, 2025Malware Analysis For Remcos Remote Access Trojan (RAT)
Tech NewsAugust 17, 2025Malware Analysis For Remcos Remote Access Trojan (RAT) Tech NewsJune 10, 2025How to register and install iOS 26, iPadOS 26, and macOS Tahoe
Tech NewsJune 10, 2025How to register and install iOS 26, iPadOS 26, and macOS Tahoe Tech NewsJune 1, 2025How to Install Cisco and Juniper Images in EVE-NG
Tech NewsJune 1, 2025How to Install Cisco and Juniper Images in EVE-NG



6 Comments
Rose Martine · November 8, 2019 at 10:43 am
Hello there, just turned into alert to your blog through Google, and located that it’s truly informative. I am going to watch out for brussels. I will appreciate for those who proceed this in future. Lots of other folks can be benefited from your writing. Cheers!
Alisha Ross · December 9, 2019 at 11:34 am
Someone necessarily assist to make critically articles I would state. This is the very first time I frequented your website page and thus far? I amazed with the analysis you made to create this particular put up incredible. Great process!
g · June 15, 2020 at 6:39 pm
I pay a visit each day a few websites and information sites to read
posts, but this weblog provides feature based writing.
g · June 16, 2020 at 1:11 pm
There is definately a lot to know about this topic. I like all the points you have
made.
g · June 17, 2020 at 5:22 am
Oh my goodness! Awesome article dude! Thanks, However I am encountering troubles with your
RSS. I don’t understand why I can’t subscribe to it.
Is there anybody getting similar RSS problems?
Anyone that knows the answer will you kindly respond?
Thanks!!
g · June 17, 2020 at 3:12 pm
Truly when someone doesn’t know afterward its up to other users that they will help,
so here it occurs.